We made a cold Russian soup!

The Preamble
@ Nationwide Digital, the NDAP team, build a common platform for all digital journeys to develop on, it's a challenge with new CVEs being released daily for so many components as-well balancing the new feature demand from our customers. It's hard to work on new features and tech spikes in our space when we're trying to follow a security cadence that's entirely influenced by things outside of our control.
I'm going to do a whistle-stop article about some our thought leadership in the platform space, how we tackle that challenge and why I hired a ton of career developers to build platform rather than traditional cloud infrastructure or "DevOps" folks.
What is my DevOps
When I inherited the foundations for NDAP (Nationwide Digital Accelerator Platform), there were a couple of immediate challenges surfaced, the first was that we were spending a huge amount of time keeping up with patching, the second was that some environments were deemed more important than others and we'd managed to manifest the all too well known double hop between them.
It struck me that we very much had a pets not cattle situation on our hands and that we were building things instead of a codebase to build the thing.
I made some relatively quick changes, we stopped hiring folks positioned as infrastructure or cloud engineers or "DevOps engineers" and started hiring career developers with cloud experience. Why? I don't want to generalise, but I'm very much of the opinion shifting things left into the development cycle improves quality and instils a sense of ownership.
Immediately we started to get tests written for our terraform & groovy, it opened a ton of options in terms of approach to solving problems which is why we're able to build the two products I'm going to talk about in this blog.
Counter culture is one of my favourite tools for inverting the cultural norms and creating a statement, "We're Different!". In that spirit; and inspired by many fabulous cocktails after hours with the team, we chose to call our two products Okroshka & Solyanka after russian soups.
So let's express some of the challenges around building a platform in a regulated financial services institute. Application building is a very well understood and mature space, build an app, use lots of super cool ways to de-risk experiments and iterate that app.
Conversely, building platforms is a much less mature space to work in; the benefits make a lot of sense when you have multiple applications or digital journeys sharing services and functionality.
Most regulated industries will operate within frameworks that are designed to keep them running in a compliant way; an example would be the Cloud Security Alliance Cloud Controls Matrix.
Generally, a controls frameworks will express a risk, followed by relatively high-level control to mitigate the risk; finally, guardrails are required to meet the control.
To counter balance extreme risk taking in the organisation, MRTs or Material Risk Takers are identified, people who are accountable for actions that can materially affect the institute.
These folks generally have a bonus structure in place, part upfront, part deferred and also the prospect of prison because the buck now stops with them. The sentiment is you must understand and mitigate the risk you are accountable for, good thing happen when you do, and bad things happen when you don't.
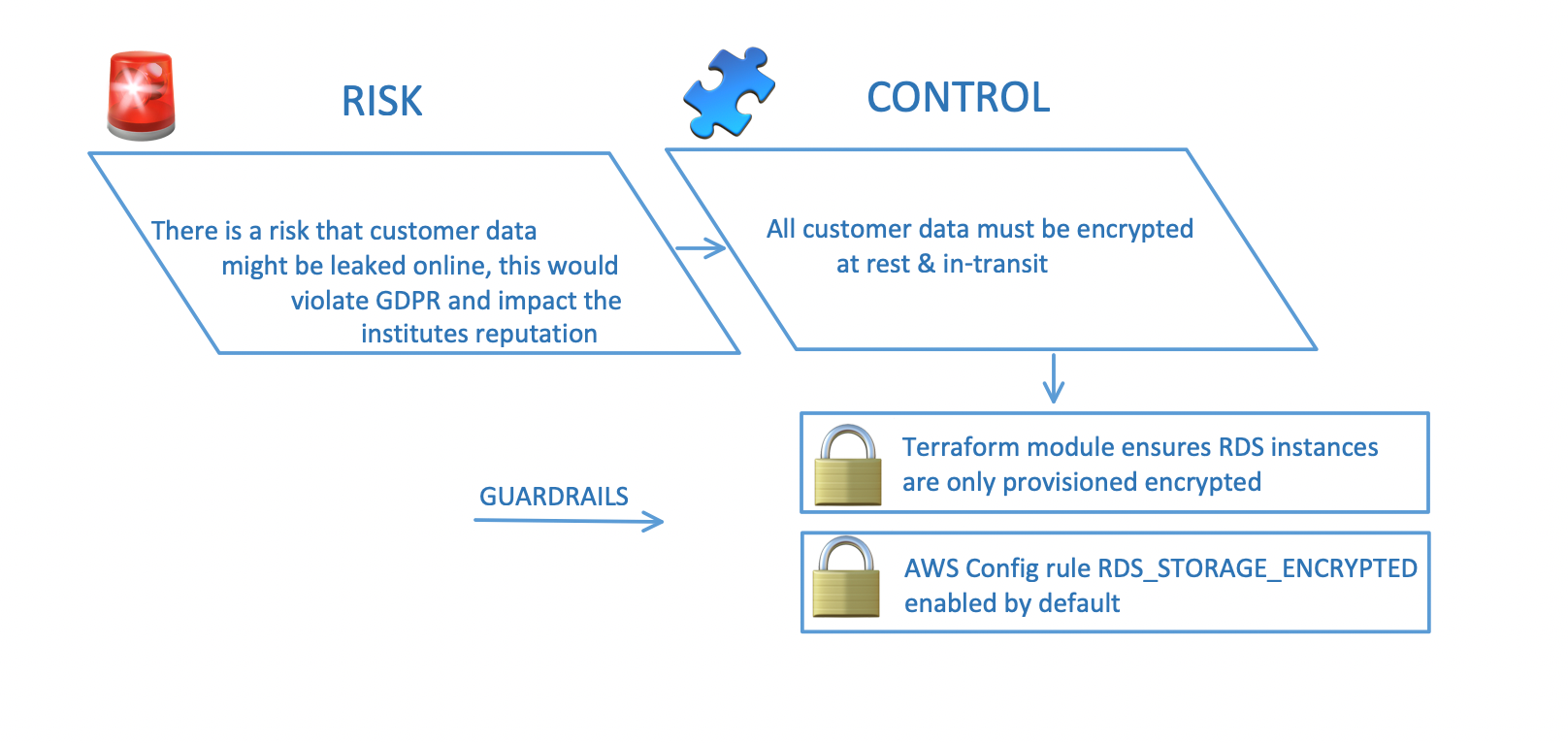
Risk
Let's take the example of customer data held in the cloud; there is a risk that customer data is exposed publicly, and the institute's reputation is damaged.
Control
Customer data should be protected and encrypted in all datastores and in-transit.
Guardrails
- Terraform module defines all RDS instances are encrypted by default.
- AWS Config has the "RDS_STORAGE_ENCRYPTED" rule specifying that all RDS instances should be encrypted at rest.
Back in the application world, I understand how to operate a single environment rather than having multiple hops to get to production. I know how to build confidence at every stage of the engineering process to make sure we're doing the right thing and minimising our risk of screwing up production.
Doing the same for a platform is a unique challenge, sure plenty of people have products that will build you a platform, but how many let you bake in those guardrails, how many will let you provision a k8s cluster with your Open Policy Admission controller policies defined out of the box? #GlueRequired
The sentiment of the problem we are solving is, as an organisation we don't have a flexible fungible view on what platform should be, we have an incredibly prescriptive non-flexible view etched in a stone tablet.
We also have a ton of shared things, implementing them again for each digital journey would violate the DRY principle (do not repeat your self) in addition to increasing risk in that they might be implemented in a different way and increase our attack surface.
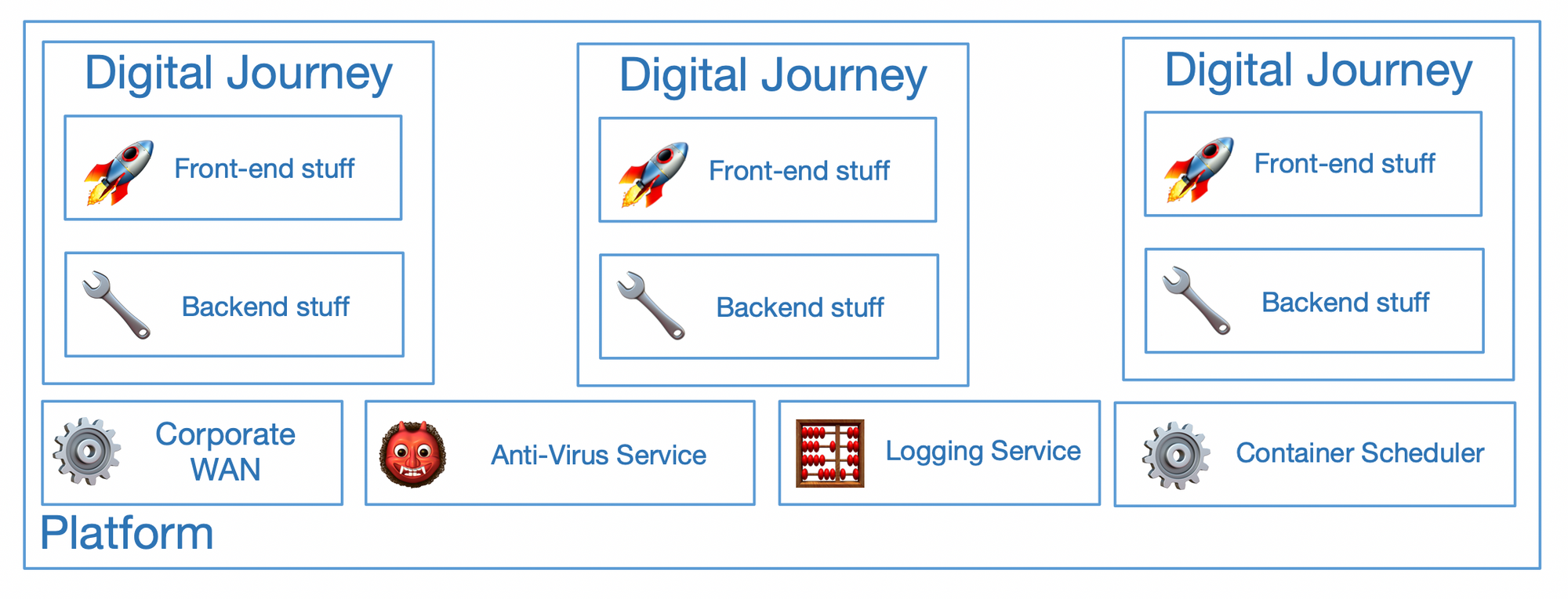
Okroshka

The first part of platform building we solve with Okroshka; Okroshka is a massively opinionated slice of what we define platform to be, there isn't any flexibility besides what you bring to the party (App-Centric Terraform, Namespaces, RBAC, Network Security Policies).
Okorshka is a bit like glue; we glue things like Terraform, KOPS, Helm together as well as some post-install actions and VPC peering + those things mentioned above a digital journey might need to define in a k8s cluster.
Now here is where things start to get cool, Okroshka will give you an idempotent instance of the platform, zero-config. It just pulls your repo and our common platform repo and builds you a cluster, and like docker, we give them a random name.
The mindset behind the arbitrary naming is to prevent you from calling something prod and giving it meaning, and everything is cattle, not a pet. Far too often, the importance of something is derived from its name. In this case, it's simply not possible to start down that bad path.
Solyanka

Solyanka allows us to test everything, both at a K8s level and at an AWS level and even things that touch multiple systems, for example, we should see an alert if that an AWS Config rule has been violated.
That alert should also bubble up to CloudWatch and the ELK stack; all of those expected outputs can be asserted to be true.
Let's touch on that risk example earlier of leaking customer data. With Solyanka we can do the following:
- Use our terraform module to provision a new RDS instance and ensure no alerts are triggered.
- Query the AWS API to ensure the instance provisioned by RDS in encrypted.
- Provision an unencrypted RDS instance and ensure that the AWS Config alerts are triggered.
- Query CloudWatch and ensure the alerts have been logged.
- Query ElasticSearch and ensure the AWS Config alerts exist.
Solyanka comes with unique challenges; we have monolithic test suits that represent massive integration style tests to assert that our platform meets our controls framework.
Unlike in the application space, we can't decouple or decompose a lot of these tests, many of them require configuring the cluster in a specific way and testing that it behaves as expected; testing a network policy in a namespace for example.
With that said, we can parallelise some tests; others are tagged as dirty, massively invasive or that they should run in isolation. We then build an acyclic graph that represents our test plan and deploy to a new region.
Touching again on behaviours we're looking to bake in early, by deploying to a new region we ensure that we can spin up and tear down all of those platform dependencies nightly keeping them fresh. This does, however, come at a disadvantage in that some services aren't always available in both our regions; lack of parity makes some testing impossible.
Solyanka's isolation or potential to end up like an iceberg with no connection to the mainland (think network isolation) means that often we have to rely on logging to figure out the state of the current graph, logging JSON from stdout means we can just pick up those results from ELK or just query the pod via the API.
So in tandem, Okroshka & Solyanka let us, as code, using industry-standard tooling define what platform should look like, glue all those distinct layers together. Assert that all of those things glued together do what we want them to do and evidence that our guardrails work as expected.
The last challenge to address is upgrading and maintenance, our strategy is pretty simple in this space, don't! It's way too much risk.
- Provision a new instance of the platform using Okroshka
- Deploy your application to the new cluster
- Add the ingress address for the new cluster to the load balancer configuration on the global traffic manager using terraform
- Shift the traffic split between the existing cluster and the new one by providing a new weight for the two origins on the load-balancer.
We're working on the sugar between some of these steps to make the movement between clusters a little smoother, on the other hand not having sugar means we have some distinct checkpoints for human intervention and eyeballing. In tandem Okroshka & Solyanka move us closer to certifying code rather than an instance of that code. #CattleNotPets
To wrap up this article I wanted to touch on something that I find really exciting, using the Solyanka framework means that we can start to express security requirements in code and to create tests (both happy and sad path) to prove them in a continuous fashion.
I'm not part of the red team, and I don't work in security, but I am part of it and this incremental but hopefully meaningful contribution to platform security hold up my part of that relationship.
Aubrey x
Bonus Thoughts
Patching was taking up a considerable amount of the teams time, It was also super hard to onboard new engineers and provide them with an environment where they could safely learn to change the platform because we only had pets. That caused us an even more significant bottleneck in that we couldn't parallelise feature development because of environmental clashes and lack of environments.
I loathe a double hop problem, a double hop is when you move between environments which have different configurations so what worked, and was configured one way in the former environment is different in the second environment, so you're trying to hit a moving target.
We had a severe double hop problem in that instead of using terraform workspaces we had separate folders to represent environments that had a different cut of code in each one, from a behavioural perspective this isn't something that will encourage consistency, terraform workspaces would virtually enforce it.
I built NDAP using a generalist squad model rather than specialist, our squad model means we can run a whole bunch of feature work or BAU in parallel as long as we can provision clusters quickly enough and with enough isolation for folks to work quickly.
Moving to a model where we don't patch an instance of a thing, we just build a new thing and move sideways make so much more sense from a risk perspective and also fits nicely with the mantra of it it's not your core business, don't build it or run it. It also encourages us to be more stateless and less stateful.
Granted, building Okroshka and Solyanka sort of violate the 'don't build frameworks' sentiment drilled into me from years of development but in this case, it makes some sense as what we're trying to do doesn't exist anywhere else, in addition, we're just glueing things together rather than reinventing the wheel with Okroshka.
Final thought, platforms make a lot of sense for us because of the number of digital journeys we are building and have built, to keep people working in a consistent way and to start to extract some of those shared benefits from the functional overlap between journeys and platforms. However, if you're only rocking a single journey or product, don't build a platform, save the time & effort and keep working at App level.
Enjoying these posts? Subscribe for more
Subscribe nowAlready have an account? Sign in