DevSecOpsDaysLDN

What a week and thus a weekend of crazy content creation, first admission, I am absolutely the type of speaker who does their slides the night before I'm due to give a talk; that means I've done this talk twice this week already!
The second admission, It's way more fun to see me do this or any of my talks live, if you're lucky there might be a video on my speaking page eventually in case you missed out or can't take the time out to follow me to an event somewhere.
So without further ado, this is talk is called "Hold on, I took the blue pill!!!", I had maybe 2-3 months to write this talk, and the content was a mystery until the last moment (or secure by default). Primarily I thought since I've never been on the red team and given the emerging state of DevSecOps it would be fair to assume many people had this movement either hit them on the ass or didn't know where to start.
Contained within are a bunch of great things you can start thinking about today and actioning straight away, it's not a definitive list by any means but probably not a dangerous place to start.

Technically this is my third admission of the post, but the first two were just guilt and puff, so remember, I don't work in the security industry, security is one of my responsibilities and logically it's somewhere in my work-chain. I do my best to keep up to date and current which brings us nicely onto the next slide.

I'd like to coin a new phrase here 'Blue by default' this is when you don't have a RED team which makes you the new defenders of all things good, safe and secure.

The challenge with Security is the cadence; it's a total mismatch when it comes to what development and what that should look like. When it comes to platforms in general; I find that each one has a rhythm that everything else sort of follows, from development through to testing through to support. You find a steady build cadence which flows downstream.
Now the things that tend to disrupt your rhythm (this isn't an advert for Senokot, promise) are external factors; retail has Christmas, easter and black Friday for example, now if we turn our heads to security; it's evolution something almost exclusively influenced by external sources.

Take a look at the number of open source projects, disclosed breaches or CVE's, every single year, year on year they are growing and in some cases doubling. Hopefully, you didn't just realise we're in the middle of a war. Don't worry private Ryan, I've got you!

I'm going to attempt to walk you on a journey through some of my thinking around building platforms and microservices, and there will be lots of walking much like the Hobbit, again let me be super clear, this isn't extensive, and there is always more you can do to innovate.

Let's start by running through common attack vectors, and this is really how I'd approach most new things, from microservices through to whole platforms. I also find a look at human behaviour to be helpful. Here is an example, people sending encryption keys and secrets via slack and email, why do they do it, because it's easy and there isn't a better way, how do we mitigate? What would make a killer solution?
I see 3 points of friction, creating them, sending them to other people, consuming them in a pipeline, each one of these is a fantastic opportunity for some good old fashion corner cutting or stupidity. By using something like Credstash or Keyvault in the code for secret consumption we provide a great way to allow developers to pull & run without the hassle of setting up local keys and secrets, it also uses their user context and not a role or service principal.
The point I'm attempting to make is that we want to look for all the friction points that exist and do our best to mitigate them or at least call them out and say we did our best but a little friction remains, please don't cut corners.
Want people to stop sending keys in slack, give them a secure way to send them in slack instead.

For our next category we have supply chain attacks, best way to visualise this in your head the distribution model of your local supermarket, if you wanted to taint you competitors product you wouldn't hit a single local store, you'd go after the warehouse which acts as the product distribution hub for all for all the stores in the country. Supply chains attacks are precisely that, getting something nefarious going on early and letting that flow downstream.

Taking our NodeJS workflow, things start very early for us with our local machine package manager, homebrew on OSX or chocolatey on Windows. We haven't even written a single line of code but imagine naught stuff that could take hold, someone compromises NVM, you install what you think is the latest version of NodeJS, instead it downloads a dirty compromised version of node that looks legit and feels legit but is secretly shipping object dumps off for analysis in Bad Actor Central, Naughtistan.
Things don't stop there, in April 2016 80% of the official images on DockerHub contained at least one high vulnerability, right! Did you just have a sinking feeling too, not great stats for the blue team, thankfully a month after that study was done security scanning tools were introduced on DockerHub.
Finally, NPM, PIP, GEM, APT all of our package managers at code or os level again are ripe and ready for the same sort of supply chain exploit we've just discussed.
So how can you protect your self, let's use docker images as an example, Clair and DockerBench provide two impressive sets of capabilities to check for CVE's, configuration gotchas etc.
Node Security Platform has just been acquired by NPM and is being folded into the platform if you're using NPM 5 and 6 and suddenly see a lot of red in your build outputs it's because the package manager is now checking and reporting on packages you're consuming and their known vulnerabilities.

Endpoint style attacks, the baddies on the red team are looking for a way into your infra or application via anything public or accidentally public. Alongside directly compromising an available endpoint the baddies are also looking for anything that gives them a clue as to your architecture or web server you're using. "X-Powered-By" is frequently send by web servers, it's the internet equivalent of "sent from my iPhone", why give up the strategic advantage.
Dirty unescaped inputs, SQL injection attacks, lack of schema validation, this is where much action is going to happen.
"OK Aubrey, I got the message, if I do nothing eventually I'll get consumed by the black fog, what do I do?" good question, I have your medicine just here.
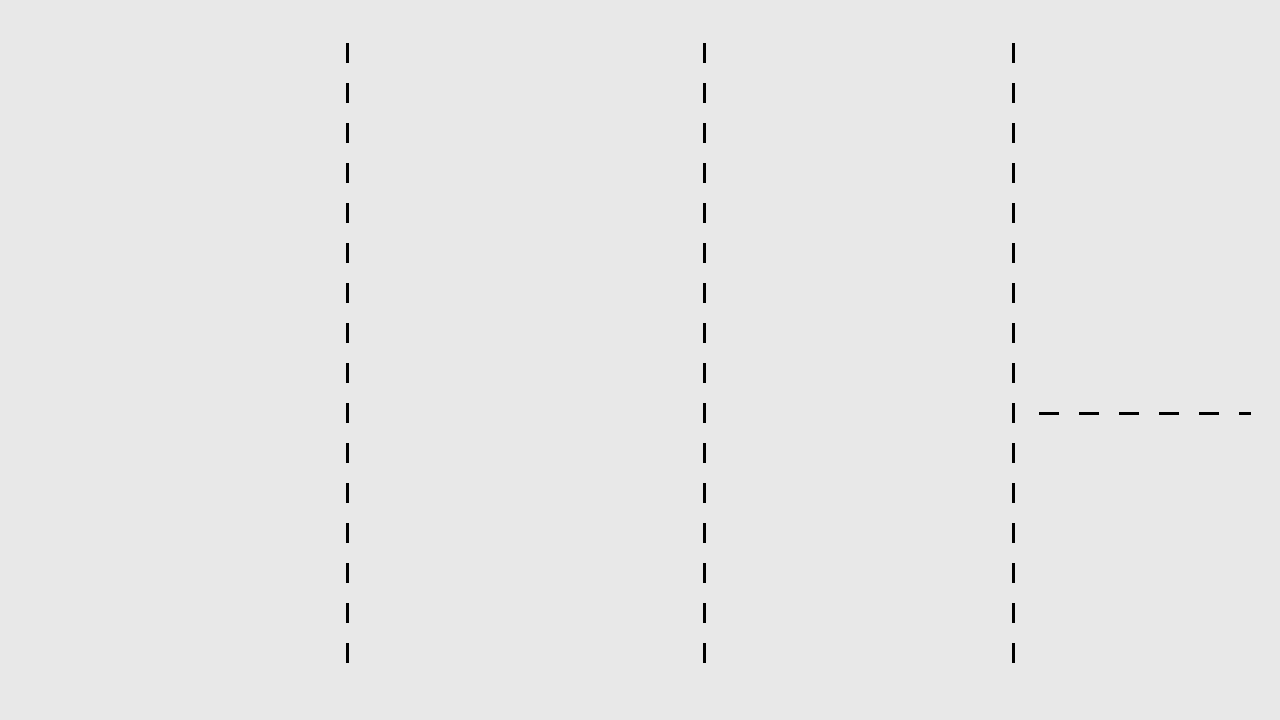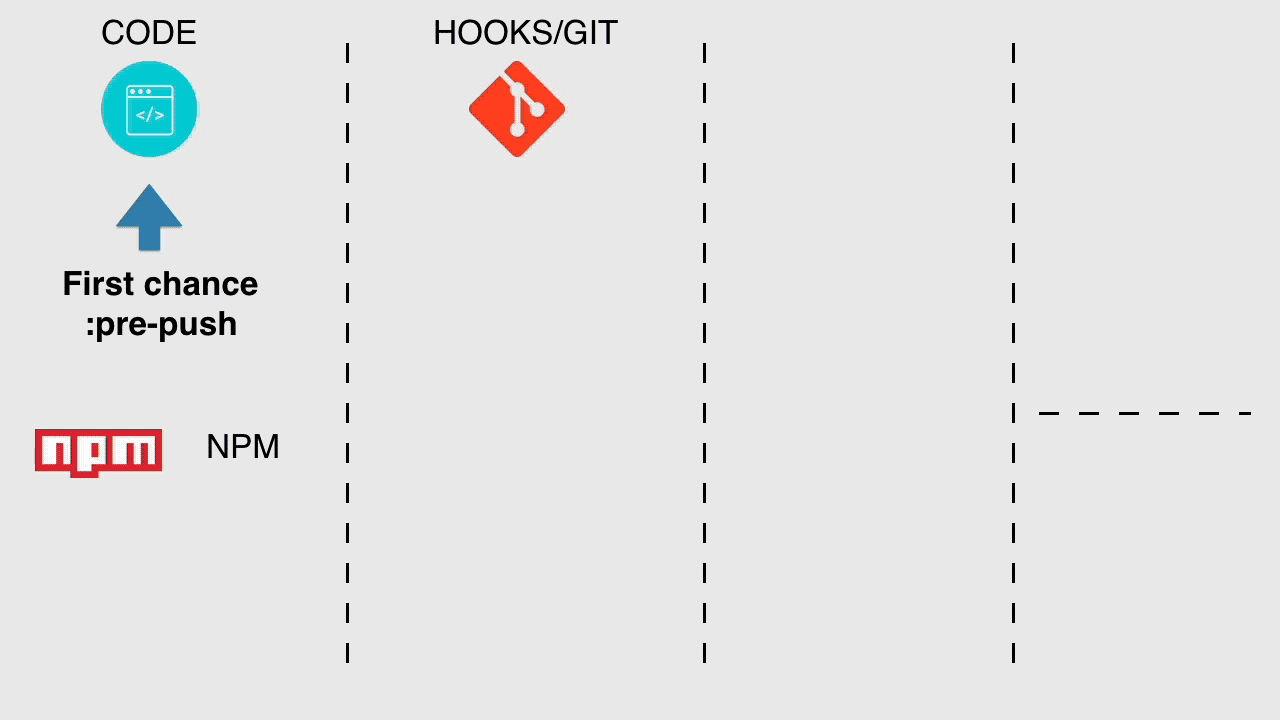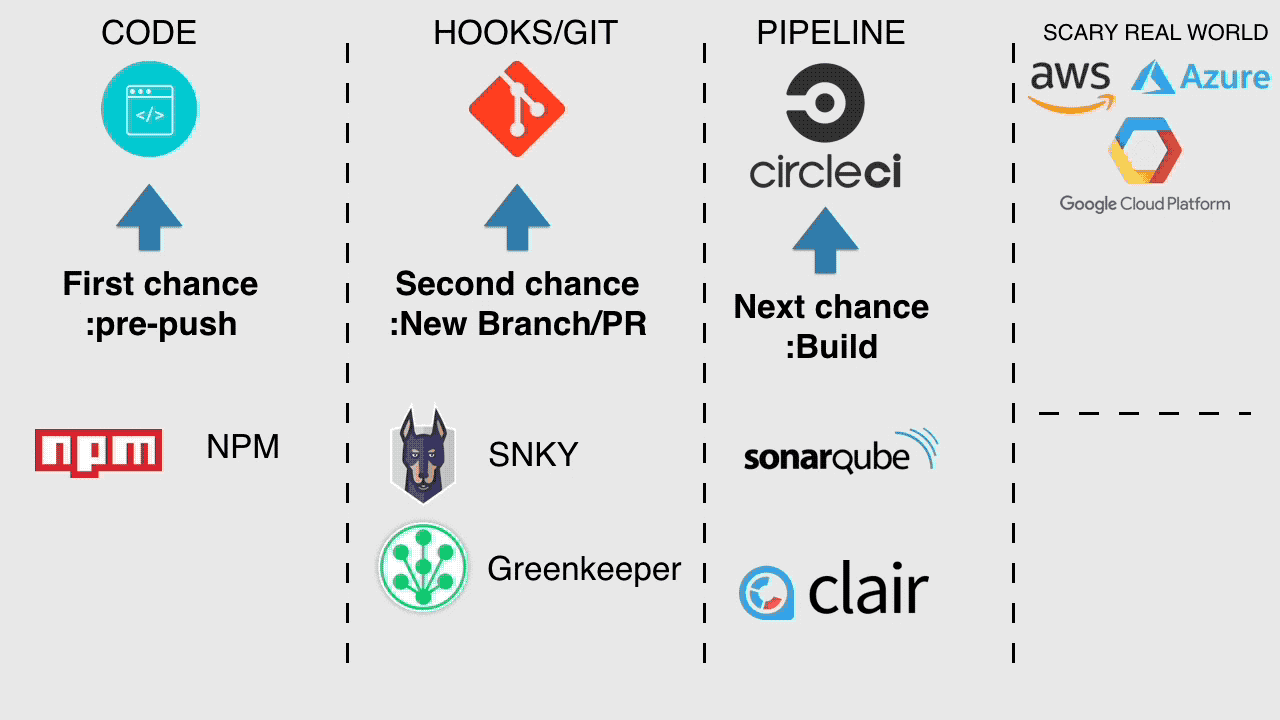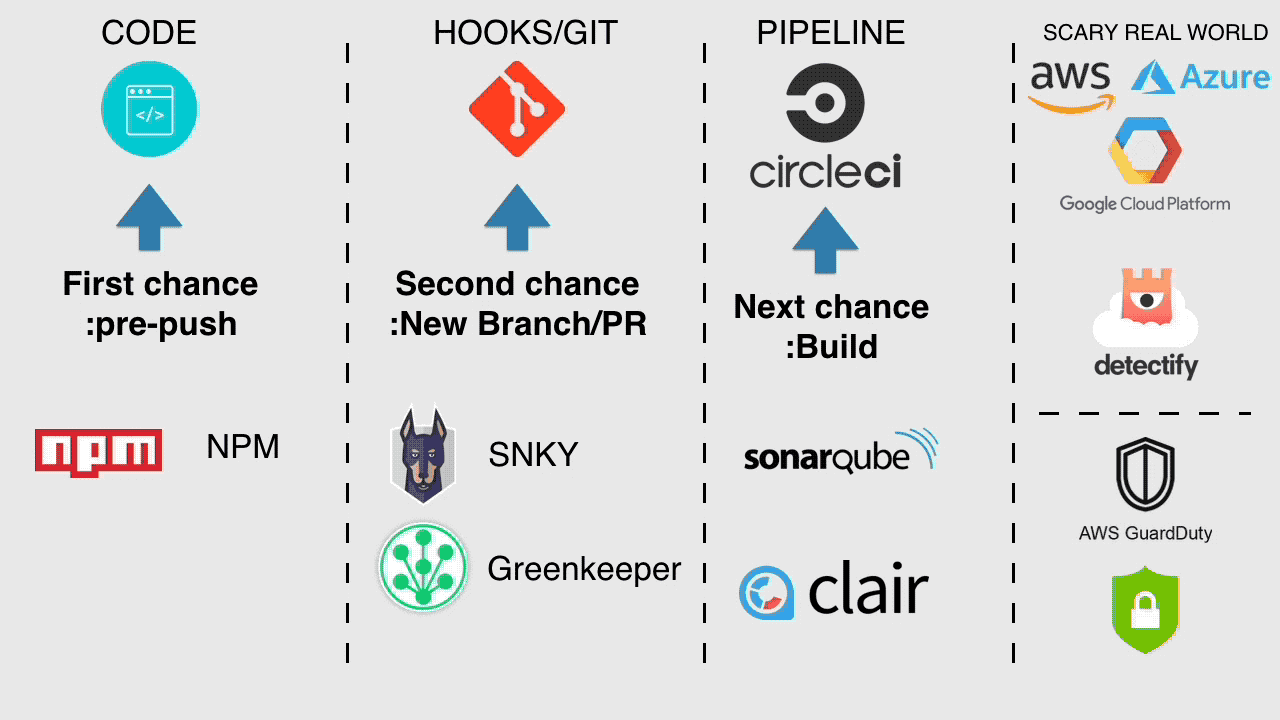
So let's look at our first chance to start getting secure, pre-push, a simple git hook that's when we do a git push but before that action takes place, this is the last stop between our machine and the code repo, so it's a great place to check what we're pushing is of the right quality.
I'd run your normal stuff, lint, tests and coverage report etc but also there is nothing to say you can't reject a push based on the NPM's vulnerability output, npm audit is your friend here.
If you have access to SNKY then again, run a scan before you push to make sure you're not introducing vulnerabilities, there is obviously an overlap between npm/nsp and SNKY, my advice is to use what works for you.
Moving on, our commit hit GitHub or wherever your remote lives, here is our next greatest opportunity to do something secure, let's take a two-pronged, trigger a scan our of microservice using SNKY and the same for Greenkeeper, SNKY as we discussed will handle security and also raise a PR when we can update a package that has been fixed or has a fix available.
Greenkeeper is an excellent integration, it scans your package.json and raises a PR for new versions of any packages you're using based on semver. Sweet little security hack to make life easier for developers and also an excellent way to see if you can update straight away as the PR greenkeeper raises will trigger your tests so you can merge with confidence.
Our next chance to get secure is in the pipeline, let's run Clair and DockerBench against our container, do we need run our container as root? Probably not, does our basic web server need the chown capability docker provides it by default probably not, and docker bench hilight a lot of this best practice for us?
Finally for the pipeline, let's run SonarQube against our code and hopefully catch any glaring mistakes, unsanitised inputs, external resources consumed, that sort of thing, code analysis.
Once we've deployed our application we can launch an external attack using Detectify; these guys use ML from some of the best-known attacks vectors in the world as well as some of the least known to simulate an external attack on our microservice and report back to us. You could stage this deployment, run the external attack and deploy based on a clean output or not deploy and triage.
Next and last in this example is GaurdDog, Trust Advisor, Inspector, Azure Security Center and GCP Security Center. Look at all that tooling; you can run your VPC logs through some of those tools to catch behaviour outside your known activity baseline. We're getting to get notified of silly things like 0.0.0.0 ANY ANY rules in our security groups. Our public clouds are also fighting for great security so we should at a minimum make sure we set up these tools as foundational security pillars on our platform.
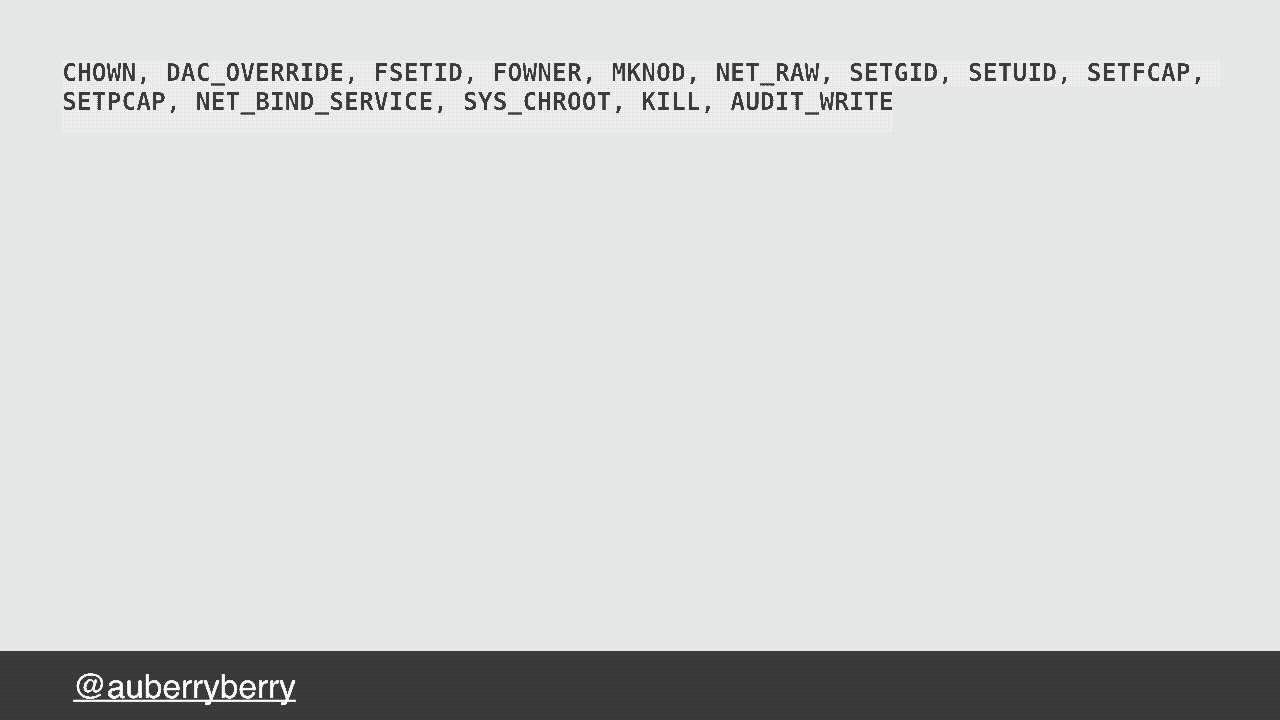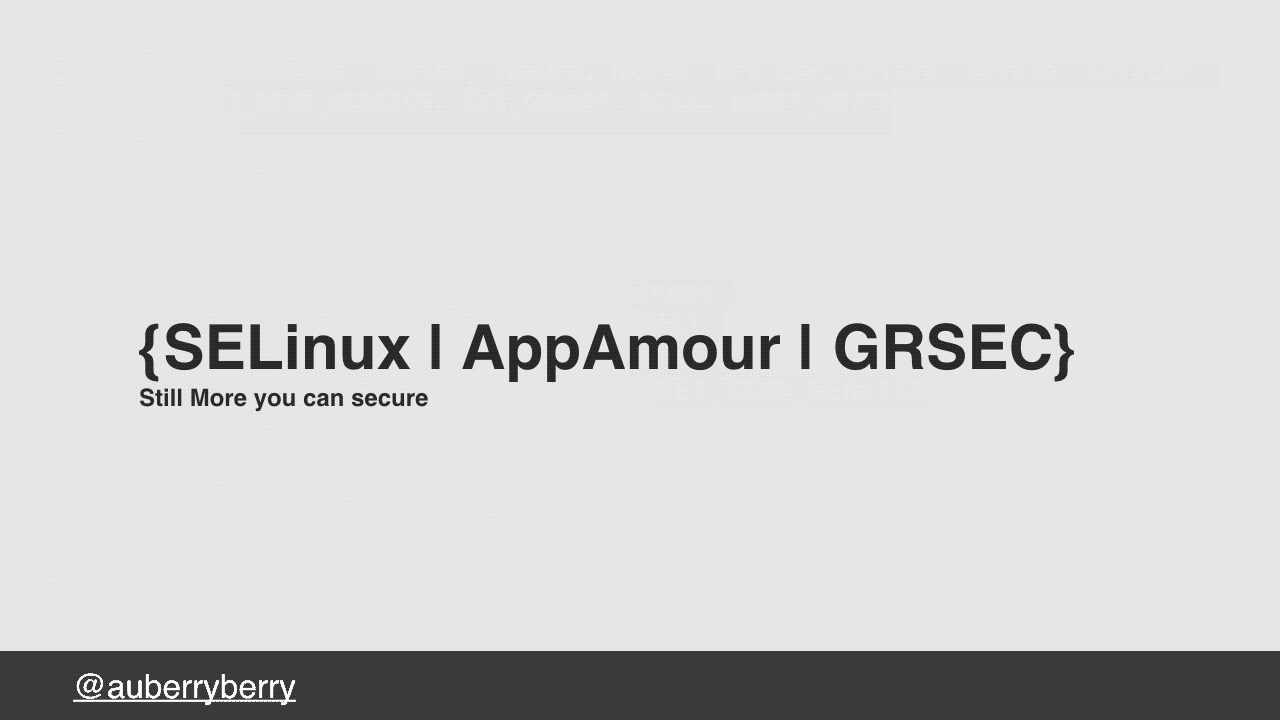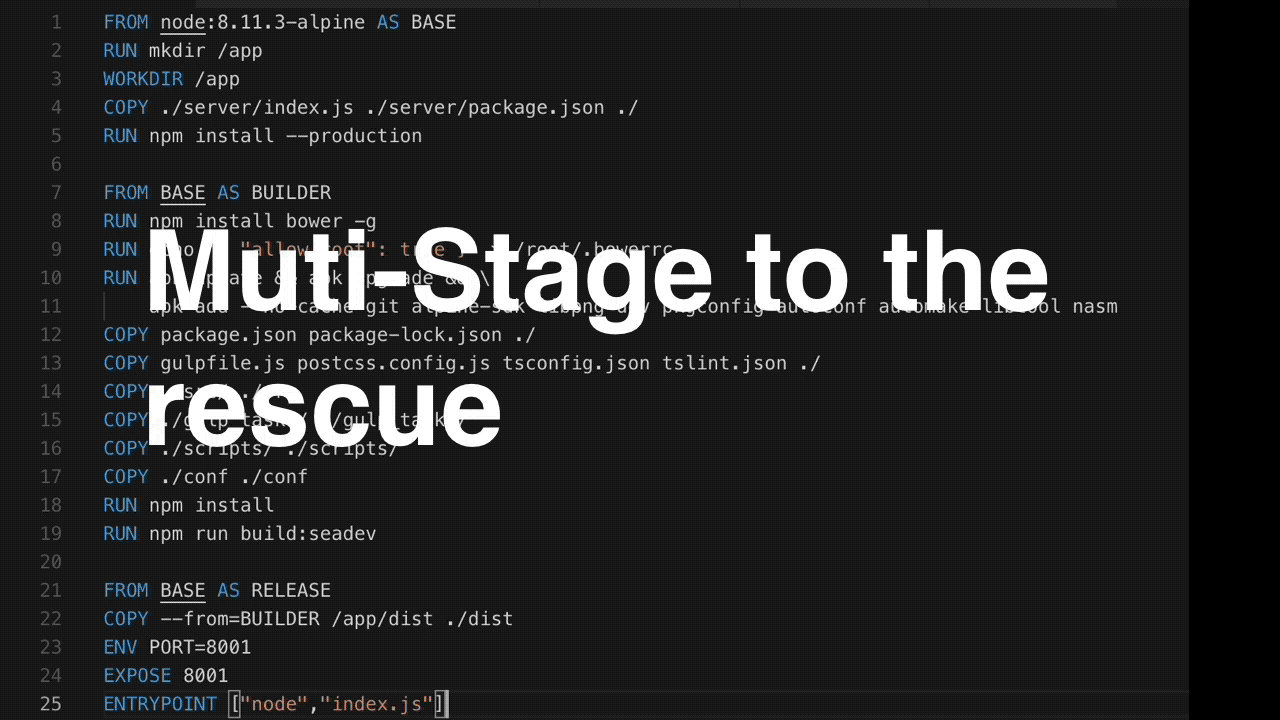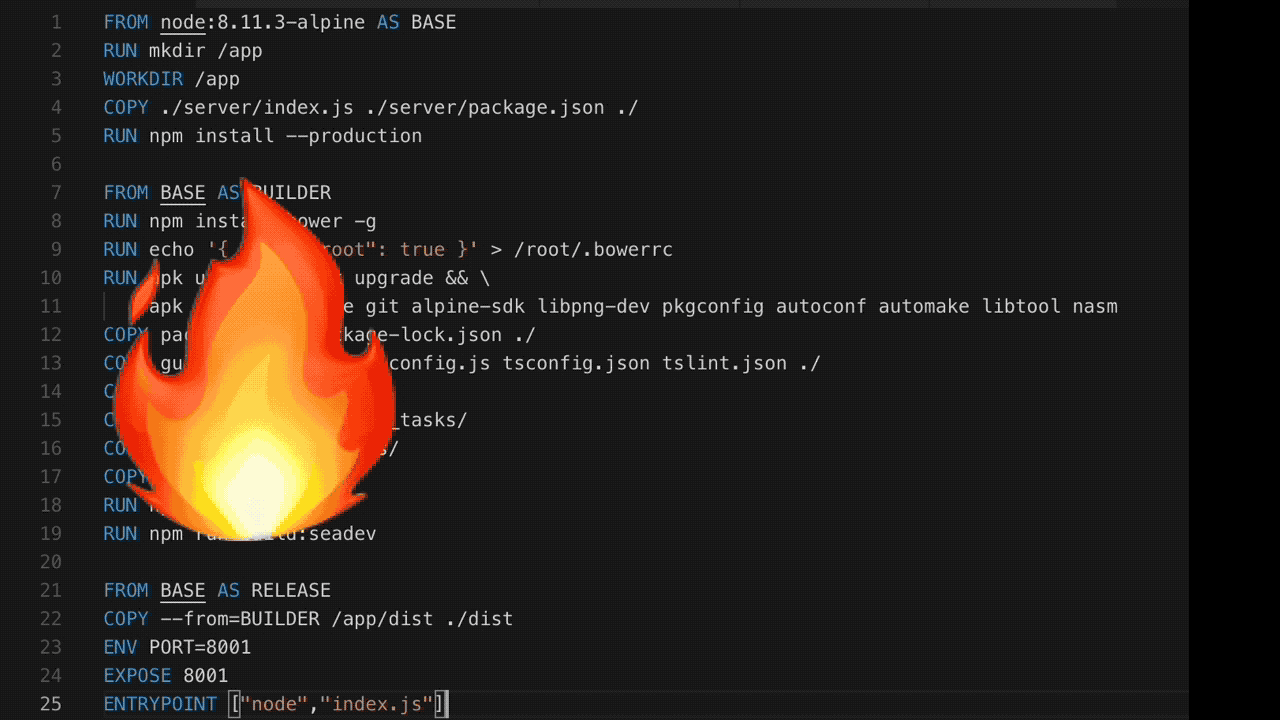
On Docker, as I previously mentioned docker by default gives you a whole host of capabilities, the chances are you don't need most of them, you might only need one of them, NET_BIND_SERVICE. To adjust these it's not the image we need to focus, more the point where we run the image. Let's look at a deployment.yml for Kubernetes; we can provide a security context for our pod that removes all capabilities and restricts our pod to only providing containers with the NET_BIND_SERVICE capability, excellent.
We're always running on the assumption that everything can and will be compromised so at each stage of everything ever we want to make it difficult for attackers or at least slow them down and make them work hard. If someone on red is working hard, then there is a good chance our logs will pick that up and the aforementioned activity monitors will kick in and let us know.
Once you're past security docker you can still look at running SELinux, an App Amour profile or GRSEC patches, there is always more to do. Remember containers are not like VM's they are running on the metal, not an abstraction so we should be even more careful than in VM Land.

Infrastructure, if you've got to this point in the talk then well done, you're committed and hopefully either learned something or you know and have done everything, and you're in a great place, sir or madam take a bow.
How do we secure our infrastructure? Well, as I mentioned earlier some of the cloud-based tooling from Microsoft, Google and Azure depending on your choice of public cloud can help you out here and catch some poor design decisions.
If you're using Terraform enterprise then Sentinal is a fantastic choice to protect everyone from themselves, if all your infra is running through the terra enterprise pipeline we can introduce some baseline policies via Sentinal, examples:
- No 0.0.0.0 ANY ANY Security Groups
- TLS Cipher suite cannot contain [DES 56, RC2 40/128]
Finally for infrastructure make sure you're using the right components for your maturity, don't use a Baracuda firewall if you've got no one with Baracuda experience, go with Azure App Gateway, most azure engineers will know how to work with it and the skill set is an easier one to acquire ( Wearing my CTO hat here). You could do the best security work in the world but if you choose the wrong implements that no one has experience with you stand a good chance of torpedoing your self.

Let's look at the last stop on our journey, don't worry, we've almost reached Mordor, and I'll have you back at the shire soon.
It might sound weird talking about client security, but I like to think about it like this, in the same way, you might enter my garden if I invite you in, you expect not to get take out by some gruesome circular saw booby-trap, there is an expectation by the client/consumer of our application that they are safe.
Let's look at the supply chain attack we mentioned earlier, imagine if that did happen, Bad Actor builds a naughty package, gets a reputation for contributing to a well-known package. He then introduces a dependency on this naughty package; leveraging both his reputation and the reputation of the innocent package he is targeting. We the unassuming developer pull in a new version of this package that was once safe, deploy it and boom, suddenly we're infecting all of our users.
How do we protect against something that could already be out of our hands? A CSP, Content Security Policy, we can deliver one of these without application, and when the browser loads, it will honour the restrictions inside, these could range from defining where we can load content from, to what the browser can load. Things can get a little stick when dealing with things like DoubleClick and lots of tags from Google Analytics, but ultimately I think the effort is worth it; CSP's are supported by all major browsers, so there is little excuse not to start including them. These also nip any Cross Site Scripting(XSS) attacks in the bud.

We're reaching my words of wisdom part of the talk now where I pop in some useful things that I live by when trying to do some of this stuff.
Don't try and introduce a massive programme of change; they rarely work, focus on things you can deliver that are yield immediate value, ideally business value.

Let's quickly look at the concept of building, deploying a docker container. When you hear DevOps is mentioned it's sometimes just in the context of CI/CD, sure that's wrong, but it gives us an excellent place to start winning hearts and minds with value.
We don't need to build the whole pipeline end to end, that's a lot of risk and lots of waiting for the business where they could lose faith in us. Instead, we could break this into three deliverables; each one has a value that we can socialise and spend time doing internal Public Relations on.
- Working Docker container
- Docker container being built in a CI pipeline
- Docker container being deployed to 3 environments.
- Security scanning the container in the pipeline
4 Places we can deliver some usable value that we can then take to the programme or business and say "Hey, we've proven our selves with these smaller things and now we're ready for something bigger" or maybe we just hit the low hanging fruit and the next challenge needed a little more runway, our success is bankable.

I wanted to make 3 points with this slide:
- DevOps will make shit go faster, no doubt about it!
- DevOps will quickly hi-light an upstream quality issue
- DevOps won't magically fix an upstream quality issue
So in summary, if you ship shit, DevOps is going to help you ship that shit faster and more reliably...which translates to bigger more consistent piles of shit?

Zones and Containment, think carefully about what has permission to access what in your cloud, in AWS use an origin access identity to make sure only CloudFront has access to the SPA on S3. Ensure that each task on ECS is assigned it's IAM roles by task and not by assigning them to all EC2 instances in a cluster.
Be ready to use your security group as a circuit breaker if you do detect abnormal VPC or VNET activity, make sure you have a fast way of triggering that.
Make sure you're running a WAF, and you have rate limiting rules in place for your public endpoints.
Again and I've made this point a couple of times, make sure those VPC logs are being shipped off to the network analysis tool, GuardDog on Amazon Web Services and Network Watcher on Azure.

Finally, remember how I said DevOps would help you ship shit faster, I think we need to redefine good engineering, for me Development, Security, Testing, Monitoring, Tracing, Logging, Deployment, Support are all development efforts. They are all testable efforts; they are all buildable efforts which means we can keep adding additional layers of quality on top.
So let me say this, stop doing scum poorly if something isn't working then stop it. Start KanBan, apply your WIP limit of 1, Build a single feature through to done and Mesure your success, postmortem what didn't work and commit to fixing it! Now we're learning. Repeat, at the end of the second week you should have noticeably improved and the cycle time of your team will be more clear. If your definition of done is [Development, Security, Testing, Monitoring, Tracing, Logging, Deployment, Support], then you're building in quality the furthest upstream you possibly can and everything downstream will benefit. If you aren't doing those things then you're doing development on credit, payments will be due shortly.

Thanks for reading, I know this was a huge article to get through, and it's usually a 30-minute talk for me to give. As always reach out on social media and give me feedback or criticism or hit me with your questions and I'll do my best to help out.
Bree xoxo
Enjoying these posts? Subscribe for more
Subscribe nowAlready have an account? Sign in